The Era of Small Language Models (SLMs): Why 2026 Belongs to Edge AI
Table of Contents
Introduction: The Pendulum Swing Toward Efficiency
For the past four years, the artificial intelligence industry has been defined by a single, overwhelming directive: Scale.
Since the release of GPT-3, the prevailing wisdom among the world’s largest tech companies was that intelligence was directly correlated with parameter count. If a 175-billion parameter model was good, a trillion-parameter model must be better. We entered an arms race of compute, where success was measured by the size of the GPU cluster you could assemble.
My Hosting Choice
Need Fast Hosting? I Use Hostinger Business
This site runs on the Business Hosting Plan. It handles high traffic, includes NVMe storage, and makes my pages load instantly.
Get Up to 75% Off Hostinger →⚡ 30-Day Money-Back Guarantee
This era produced marvels of engineering, but it also created an unsustainable trajectory. We built models so large they could only exist in massive, energy-sucking data centers. We created a paradigm where centralized intelligence was rented via API calls, subject to network latency, privacy risks, and ever-increasing costs.
As we settle into 2026, the pendulum is swinging violently in the opposite direction. The “bigger is better” hypothesis has hit a wall of diminishing returns and economic reality.
We are now entering the Era of the Small Language Model (SLM).
This shift isn’t just a minor technical adjustment; it is a fundamental restructuring of the AI landscape. It is a move away from centralized, monolithic intelligence toward distributed, highly efficient Edge AI. It is a future where the most important AI interactions happen not in the cloud, but locally on your laptop, your phone, and your embedded devices.
For the developer, this validates a crucial truth: engineering on constraints is no longer a compromise. It is the future standard.

The “Compute Wall”: Why Giants Stumbled
To understand why SLMs are taking over, we must first understand why Large Language Models (LLMs) hit a ceiling. The current trajectory of scaling LLMs faced three insurmountable barriers by late 2025.
1. The Economic Barrier (The Inference Cost Crisis)
Much of the media focus has been on the cost of training these models—the hundreds of millions of dollars spent on NVIDIA H100s just to create the base model. However, the real economic killer is inference—the cost of actually running the model when a user asks a question.
Every time a user asked ChatGPT to summarize an email or write a Python function, that request had to travel to a data center, spin up massive GPU resources, generate the tokens, and travel back. This is incredibly expensive. For companies like Microsoft or Google, integrating LLMs into free products like search or office software became a financial black hole. They were subsidizing billions of dollars in compute costs that advertising revenue could not cover.
The industry realized it was using a sledgehammer to crack a nut. You do not need a trillion-parameter model with PhD-level reasoning capabilities just to autocorrect a text message or summarize a PDF.
2. The Energy and Infrastructure Barrier
The physical reality of data centers became a limiting factor. By 2025, AI data centers were consuming electricity rivaling entire nations. Grid operators began denying requests for new server farms due to lack of power capacity.
Furthermore, the latency inherent in cloud-based models broke the user experience for real-time applications. A developer using an AI coding assistant cannot afford to wait 800 milliseconds for every line of code completion. The speed of thought requires instantaneous response, something physics dictates the cloud cannot provide reliably.
3. The Data Privacy Barrier
Perhaps the biggest driver for corporate adoption of SLMs has been fear. As LLMs became integrated into workflows, companies realized they were hemorrhaging proprietary data. Every snippet of code sent to GitHub Copilot, every financial document summarized by ChatGPT Enterprise, was potentially data leaving the company’s secure perimeter.
Major corporations began banning cloud-based AI tools, creating a massive vacuum for a solution that offered intelligence without data exfiltration.
These three barriers created the necessary pressure for innovation in the opposite direction: radical efficiency.
Defining the SLM: What Makes a Model “Small”?
Before analyzing the impact, we must define the terms. In 2026, the definitions have shifted.
- Large Language Models (LLMs): Generally considered models with over 70 billion parameters (e.g., Llama 3 70B, GPT-4 variants). These require massive, multi-GPU setups just to run.
- Small Language Models (SLMs): Models optimized to run on consumer-grade hardware with limited RAM. Typically under 15 billion parameters.
The sweet spot for SLMs in 2026 has settled around the 7B to 8B parameter range.
Thanks to breakthrough techniques in quantization (reducing the precision of the model’s weights from 16-bit to 4-bit or even 2-bit) and knowledge distillation (training a small student model on the outputs of a large teacher model), these “small” models are shockingly capable.
An 8B parameter model in 2026, such as the latest iterations of Mistral, Gemma, or Llama, outperforms the massive 175B parameter GPT-3 of 2020 in almost every benchmark, while fitting comfortably into 8GB–16GB of system RAM.
The Hardware Enabler: Rise of the NPU
Software does not exist in a vacuum. The rise of SLMs is inextricably linked to a massive shift in consumer hardware architecture: the widespread adoption of the Neural Processing Unit (NPU).
For decades, computers relied on CPUs for general tasks and GPUs for graphics. While GPUs proved excellent at the parallel math required for AI, they are power-hungry beasts designed for desktop gaming rigs, not efficient background processing on a laptop.
The NPU is a specialized processor designed from the ground up for the matrix multiplication operations that dominate AI workloads. Unlike a CPU, it is highly parallel. Unlike a GPU, it is incredibly power-efficient.
The “AI PC” Standard
By 2026, virtually every new laptop CPU architecture—from Intel’s Core Ultra series and AMD’s Ryzen AI to Qualcomm’s Snapdragon X Elite and Apple’s M4 silicon—features a dedicated, powerful NPU.
This hardware shift is critical. It means that running an SLM locally no longer requires pegging your CPU at 100% and spinning your laptop fans up to jet-engine speeds. The NPU handles the inference quietly in the background, sipping single-digit Watts of power, while your CPU and GPU remain free for other tasks.
Useful Links
- Microsoft AutoGen vs. CrewAI: I Ran a “Code Battle” to See Who Wins in 2026
- How to Build AI Agents with LangChain and CrewAI (The Complete 2026 Guide)
- Beyond the Chatbot: Why 2026 is the Year of Agentic AI
- Why Developers Are Moving from ChatGPT to Local LLMs (2025)
- LangChain vs. LlamaIndex (2026): Which AI Framework Should You Choose?
- Toil is Back: Why Even with AI, SREs Feel the Burn in 2025
For the developer on a standard 16GB laptop, this is a game-changer. It means you can run a sophisticated coding assistant or data analysis model locally without degrading your machine’s overall performance. The hardware has finally caught up to the software’s ambition.

The Business Case for Edge AI: Sovereignty and Speed
The shift to SLMs is not just a technical curiosity; it is being driven by hard-nosed business requirements. The “Edge AI” paradigm—running models on the end-user’s device rather than in the cloud—solves fundamental business problems.
1. Data Sovereignty and Compliance
In highly regulated industries like finance, healthcare, and legal services, cloud AI is a non-starter. Hospitals cannot send patient records to OpenAI’s servers to be summarized. Banks cannot send transaction data to a public cloud for fraud detection.
SLMs provide the solution: Data Sovereignty.
By deploying a fine-tuned 8B model directly onto on-premise servers or employee laptops, businesses gain the benefits of AI analysis without the data ever crossing the firewall. The inference happens where the data lives. This compliance advantage is turning SLMs into the preferred choice for enterprise AI adoption in 2026.
2. The Zero-Latency User Experience
In consumer applications, latency is the enemy of engagement. If a user taps a button on their phone to generate an image or translate a sentence, a 3-second delay while the request travels to a data center feels broken.
On-device SLMs provide instantaneous results. This is crucial for real-time applications like:
- Augmented Reality (AR): Where object recognition must happen in milliseconds to overlay digital info on the real world.
- Voice Assistants: Which need to process speech and execute commands without an awkward pause.
- Gaming: Where AI-driven NPCs need to react instantly to player actions.
By moving intelligence to the edge, applications feel snappier and more responsive, creating a superior user experience that cloud-tethered apps cannot match.
3. Offline Capability
The reliance on constant internet connectivity is a major weakness of cloud AI. Field workers, travelers on airplanes, or developers in areas with spotty Wi-Fi are cut off from their tools.
SLMs democratize access to intelligence by making it available offline. A developer can have a full documentation search engine and code completion assistant running on their laptop while coding on a flight, completely disconnected from the grid.
The Developer Reality: Engineering for the Edge
What does this macroeconomic shift mean for the individual software engineer in 2026?
It means a fundamental change in how we build and integrate AI features. The era of simply making an API call to openai.com/v1/completions is ending. The new skillset involves AI Orchestration and On-Device Optimization.
The New “Full Stack”
The definition of a “Full Stack Developer” is expanding to include the AI layer. Developers now need to understand:
- Model Selection: Knowing which 7B or 8B model is best for a specific task (e.g., choosing a model fine-tuned for SQL generation versus one tuned for creative writing).
- Quantization and Runtime: Understanding how to take a model and compress it using tools like
llama.cppor ONNX Runtime so it fits within the RAM constraints of the target device. - Hybrid Routing: Building systems that aren’t purely local or purely cloud.
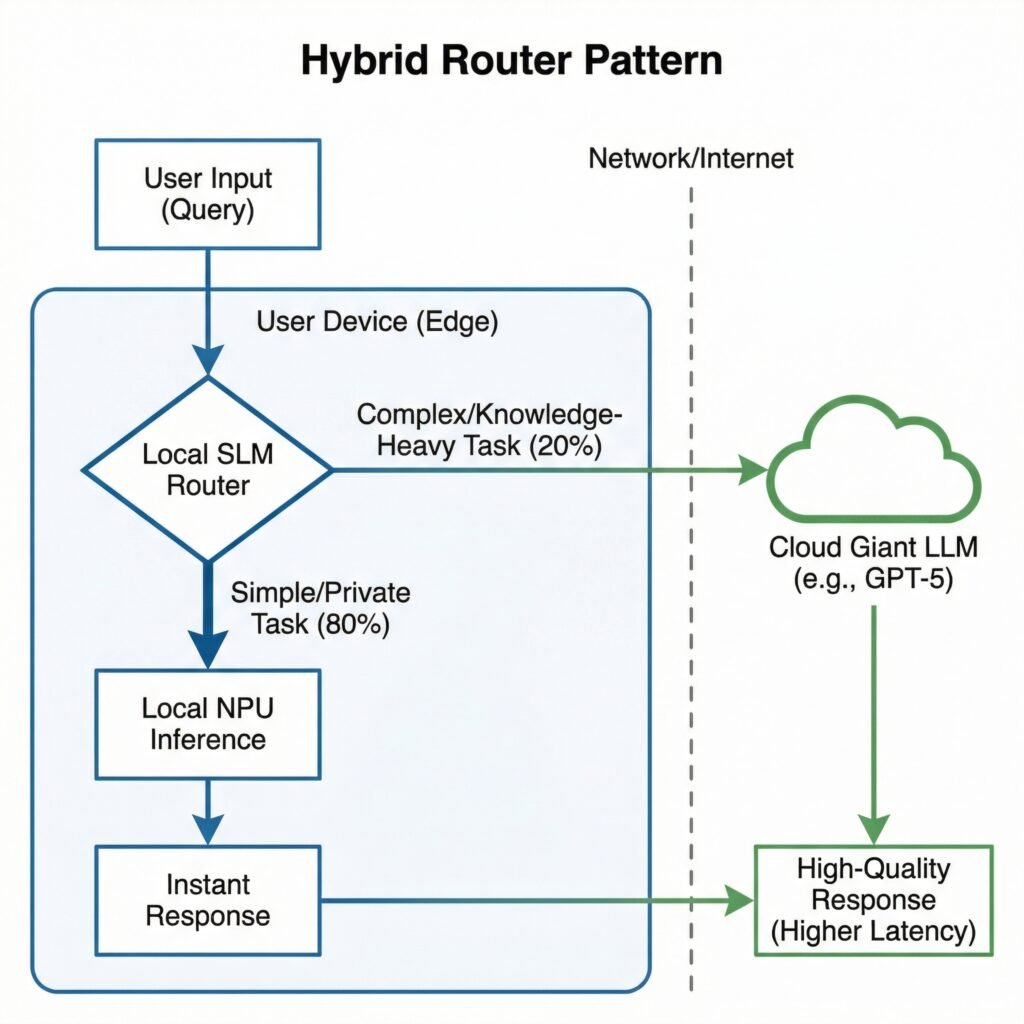
The Hybrid Future: The “Router” Pattern
The future isn’t about abandoning the cloud entirely; it’s about using it intelligently. We are seeing the emergence of the “Router Pattern” in application architecture.
In this model, the application contains a small, ultra-fast SLM running locally. This local model acts as the first line of defense. It handles 80% of user requests—the simple queries, the basic summarizations, the UI interactions—instantly and for zero cost.
When the local model detects a query that is too complex or requires deep, updated world knowledge that it doesn’t possess, it “routes” that specific request up to a massive cloud LLM (like GPT-5 or Claude).
This hybrid approach offers the best of both worlds: the speed, privacy, and low cost of edge AI for most tasks, backed by the boundless intelligence of the cloud only when necessary.
Conclusion: The Validation of Constraint-Driven Engineering
The rise of Small Language Models in 2026 is more than just a trend in AI; it is a vindication of a core engineering philosophy.
For years, the industry chased unbounded scale, assuming that throwing more hardware at a problem was the only path to progress. The inevitable collision with economic and physical reality has forced a return to fundamentals: efficiency, optimization, and intelligent resource management.
The future of AI does not belong to the developer with the biggest AWS budget. It belongs to the engineer who understands how to deliver intelligence within the constraints of the edge.
If you are developing on a standard laptop today, prioritizing efficient runtimes, managing your memory footprint, and exploring local models, you are not falling behind. You are practicing the exact skillset that will define the next decade of software engineering.
The era of the giant is over. The era of the efficient, local, and private model has just begun.

🚀 Let's Build Something Amazing Together
Hi, I'm Abdul Rehman Khan, founder of Dev Tech Insights & Dark Tech Insights. I specialize in turning ideas into fast, scalable, and modern web solutions. From startups to enterprises, I've helped teams launch products that grow.
- ⚡ Frontend Development (HTML, CSS, JavaScript)
- 📱 MVP Development (from idea to launch)
- 📱 Mobile & Web Apps (React, Next.js, Node.js)
- 📊 Streamlit Dashboards & AI Tools
- 🔍 SEO & Web Performance Optimization
- 🛠️ Custom WordPress & Plugin Development